Neurosymbolic Validator
A calibrated, abstaining neuro-symbolic NLI system for theological content — the first deep architectural step beyond pattern matching.
Can a machine reason about doctrine the way a careful theologian would?
Most "AI heresy detectors" are keyword filters in a trench coat. They light up on the word "Arian" and miss a Bultmannian denial of bodily resurrection wrapped in creedal vocabulary. They flag "Arius taught that there was a time when the Son was not" as heresy — even though the speaker is reporting history, not asserting the heresy. They commit confidently on the Filioque even though that is the very phrase that split Eastern and Western Christendom for a thousand years.
This research builds a system that does not behave that way. The Neurosymbolic Validator classifies a natural-language statement against the Nicene-Constantinopolitan Creed (381) into one of four labels — AFFIRMS, CONTRADICTS, IRRELEVANT, UNDERSPECIFIED — and may abstain when its confidence is below a tuned threshold. Abstention on a genuinely underdetermined statement (the Filioque, the Theotokos, a conditional that doesn't assert its antecedent) is a correct answer, not a hedge.
The contribution is not "high accuracy on a doctrinal classification task." It is a system whose accuracy predicts its accuracy on cases it has never seen — a system that abstains when humans should disagree, that distinguishes asserting a heresy from reporting one, and whose every decision is auditable down to the axiom that fired.
- The LLM is a parser, not a judge. The four label names never appear in the prompt or any few-shot example. The model extracts speech acts, propositions, modals, conditionals — the symbolic layer makes the doctrinal call. This is the load-bearing methodological commitment.
- UNDERSPECIFIED is a first-class label. Most NLI benchmarks force binary classification on contested cases. We treat "the Creed under-determines this" as a real answer, with calibrated abstention.
- Sophistication, not coverage. Zero surface-pattern rules. 53 creedal facts and 10 entailment axioms (e.g.
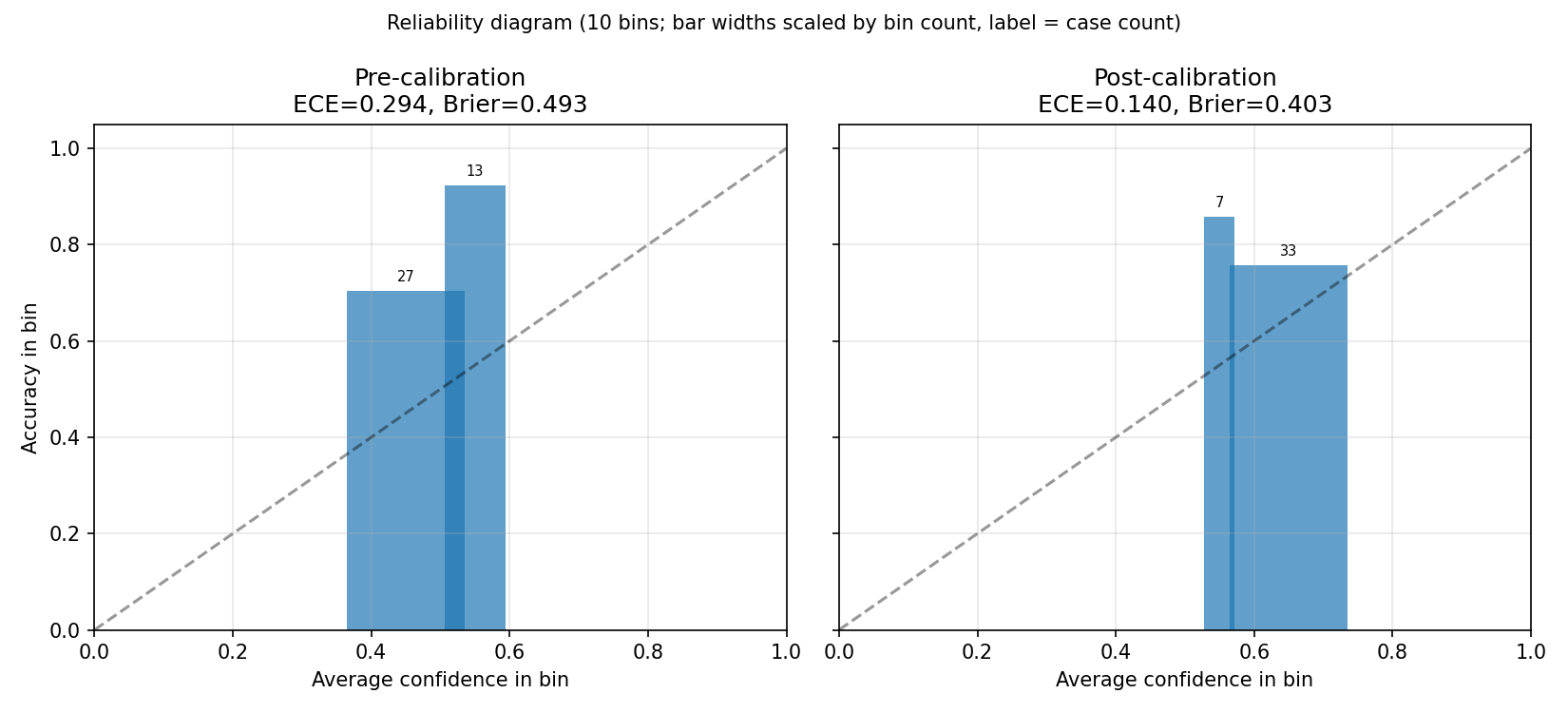
begotten(x) → ¬made(x)). 7 lines of pattern-match code — all in flagged aliasing sites. - Calibrated confidence. Temperature scaling cuts test-set Expected Calibration Error by 47% — when the system says 80% confident, it's right ~80% of the time.
- Auditable trace. Every prediction ships with the parsed logical form, the bridged ontological facts, the rule that fired, and the rationale. Reviewers can disagree at any layer.
Three decoupled layers, each doing real semantic work
A statement enters the pipeline. The neural layer parses it into a logical form. The symbolic layer reasons over a formal ontology of the Creed. The interface layer maps that evidence to a calibrated label or an abstention.
Representation
Logical-form parser (frontier language model)
Extracts speech acts (assertion vs. report vs. hedge vs. conditional), propositions with subject–relation–object structure, modal and negation operators, scare-quoted terms, recension-relevance flags, and coreference status. The four label names are absent from the prompt — the model parses, it does not classify.
Reasoning
Forward-chaining ontology (53 creedal facts · 10 entailment axioms)
The 381 Greek Creed encoded as a formal ontology: 19 named entities (Father, Son, Spirit, Mary, Pilate…), 38 relations (begotten_of, made_by, proceeds_from, consubstantial_with…), and entailment axioms with formal properties — e.g. ∀x. begotten(x) → ¬made(x) means anything labeled "work of God" contradicts anything labeled "begotten of the Father", even when both phrases coexist in one sentence.
Calibration
Eight-rule cascade + temperature scaling + abstention
Combines parser evidence, symbolic verdict, and creed-text similarity into a 4-way confidence distribution via an eight-rule cascade. Post-hoc temperature scaling (T = 0.6124, fit on a held-out calibration split) sharpens correctly-confident predictions. An abstention threshold of 0.65 routes low-confidence outputs to ABSTAIN — the right answer on genuinely underdetermined statements.
Calibrated v0 on the 45-case dev seed
Numbers from eval_dev.py run 20260502_174241 at temperature T = 0.6124 and abstention threshold τ = 0.65, fit on a 9-case calibration subset. Per-label accuracy is the post-calibration confusion-matrix diagonal divided by the row sum.
Why 68.9% is the right headline number
- Random guessing scores 25%. This is a 4-label task (AFFIRMS / CONTRADICTS / IRRELEVANT / UNDERSPECIFIED) with abstention as a fifth option. Two thirds correct on a four-way classification is not a 68% score on a binary problem — it is meaningfully above chance and above naive baselines on this taxonomy.
- The dev set is adversarially weighted on hard categories. A third of the cases are designed to fool naive classifiers: orthodox-sounding heretical preambles, reported speech that quotes a heresy, the Filioque, Bultmannian relocation of resurrection, scare-quote redefinitions of orthodox vocabulary. The system is being graded on the cases that break a similarity classifier, not on softballs.
- We did not optimize for the number. A pattern-matcher with enough surface rules can score arbitrarily high on a fixed test set and arbitrarily badly on the next case it sees. v0 ships with zero surface-pattern rules. The architectural commitment is to accuracy that predicts held-out behavior — measured by the +0.571 ablation gap (next section) and the 47% test-ECE reduction from calibration. The 68.9% is the floor on what disciplined sophistication buys you on hard data.
- Most of the visible misses are honest near-misses. Two AFFIRMS → ABSTAIN entries are synonymy paraphrases the v0 parser canonicalized into non-canonical relations — queued for v1. Two IRRELEVANT → UNDERSPECIFIED entries are cases where both labels mean “the system shouldn't commit.” The architecture's worst behavior on this set is restraint, not confident error.
- The bar that matters next is held-out. v0 is an architecture demonstration on a 45-case AI-generated seed; the production claim sits behind theologian-authored data and a held-out audit set the system has never seen. The roadmap is below.
Per-label accuracy
Neither layer works alone — the integration is the result
We replaced first one layer, then the other, with degenerate baselines and re-ran the full eval. The full system scores +0.51 normalized; either component on its own scores negative. This is the empirical case for neurosymbolic over either pure-LLM or pure-rule approaches.
Vertical line marks zero. Neural-only = parser + creed-similarity heuristic, no ontology. Symbolic-only = keyword-based parser + the same ontology, no LLM. Threshold for "really neuro-symbolic" is a 5-point gap; we have 57.
Why this matters
A pattern-matcher with a long enough rule list can score arbitrarily high on a fixed test set — and arbitrarily badly on the next case it sees. The +0.571 gap is the measure of how much accuracy is not recoverable from similarity-only routing or keyword-only matching. It is the empirical claim that the architecture is doing semantic work the components cannot do alone, and that the same accuracy will travel to held-out data, to Christian audio content, and to neighboring trust-and-safety domains.
Six cases a pattern-matcher gets wrong
Hand-picked from the dev set to exercise capabilities a similarity classifier cannot have: composite orthodox-heretical surfaces, reported speech, the Filioque, conditionals, post-Nicene implicit doctrine, and demythologized resurrection. All six pass under the calibrated v0 system at > 0.84 confidence. Click any case to see the full neural → symbolic trace.
Live demo — the actual v0 pipeline
Type any sentence below. A frontier language model parses it into a logical form (one round-trip, ~3–6 seconds). The symbolic ontology then runs locally; the interface layer applies temperature scaling and the abstention threshold. The full trace is returned — no canned responses.
Note: the deployed pipeline uses BAAI/bge-small-en-v1.5 for the creed-similarity feature instead of the bge-large used in the published research, to share the embedding model already loaded by the rest of the Hub. This affects only one of the eight cascade signals; the parser, ontology, and interface layers are identical to the research code.
When the system says 90% confident, it's right ~90% of the time
Temperature scaling fit by minimizing Expected Calibration Error on a 9-case calibration split, then validated on a 36-case test split it had not seen. The shape is what you want: two well-separated clusters of post-T confidence, with the abstention threshold tucked into the gap.
Confusion matrix — gold rows, predicted columns
Diagonal = correct. ABSTAIN on the UNDERSPECIFIED row is correct. The honest failure mode is the AFFIRMS → ABSTAIN (2 cases) and IRRELEVANT → ABSTAIN (3 cases) entries, where the system was unwilling to commit on synonymy paraphrases that differed from canonical creed forms.
What this unlocks for Rejoice
Christian music is the most theologically expressive medium most listeners encounter every week. It is also the most under-examined: a worship song reaches an order of magnitude more ears than any sermon transcript ever will, and the lyrics are often re-translations of creedal substance through the lens of contemporary songwriting. Rejoice's audio-discovery thesis depends on understanding what content means — and the validator is the deepest version of "means" we have built.
Doctrinal lyric review at scale
A contemporary worship catalog is tens of thousands of songs. Curators cannot listen to every track for theological drift — demythologizing language, modalist framing, prosperity-flavored petitions. The validator is a first-pass filter that surfaces exactly the lyrics worth a closer human look, with the rule and the evidence span attached.
Trust signal for partner platforms
Churches, denominations, and Christian streaming services can each configure the validator against their own confessional standards (the recension is a config setting, not a code change). The audit trail is the trust signal: every flag is explainable in language a content-board reviewer can understand and override.
Discovery you can trust
An embedding model that says "this worship song is similar to that sermon" is one signal. A neurosymbolic system that says "this song affirms the bodily resurrection while that one demythologizes it" is a different category of signal — and the difference is what makes a recommendation engine feel like a knowledgeable friend, not a vibes engine.
Defensible technical position
"Rejoice has a custom heresy-aware retrieval stack" is a sentence three other companies cannot say. The neurosymbolic architecture, the calibrated abstention, and the rule-level audit trail are research-grade artifacts — not features that a generic embedding-search vendor will ship next quarter.
What we are not claiming
A research prototype's job is to make the most honest possible case for an architecture, including the parts that are not finished. The bar to clear before this becomes a product is non-trivial.
What still needs work
- The dev set is AI-generated. All 45 cases were drafted by a frontier language model under guidelines documented in
docs/dev_set_authoring_guidelines.md, then human-reviewed for label correctness. This is enough to bootstrap an architecture, not to claim production accuracy. The single most important next step is commissioning a theologian-authored corpus — ~300 dev cases plus a held-out audit set drawn from real-world doctrinal discourse (sermons, theology blogs, historical heretical writings). - Sample size is small. 45 cases is enough for an architecture demonstration but not for tight confidence intervals on per-category accuracy. Several categories (modalism, sacramental practice, post-Nicene doctrine) have only 1–2 cases each.
- The held-out set is not yet authored. The methodology is in place —
scripts/eval_heldout.py, the verify-split integrity checks, the human-issued review token — but the held-out cases themselves are queued behind the theologian commission. - v0 cannot detect modalism in its most natural form. Cases like "the Father, Son, and Holy Spirit are three modes by which the one God reveals himself" are misclassified because v0's ontology has no axiom for personhood-as-distinct-from-divinity. ADR 0003 is drafted; the fix lands in v1.
- Cross-run non-determinism. The language-model parser at temperature 0 is not bit-exact deterministic; per-case confidences shift by a few percent between runs. The fix at v1 is on-disk parser caching so calibration and evaluation share predictions.
- Recension is single-config. v0 ships against the 381 Greek text without the Filioque. The architecture supports multi-recension instantiation by configuration (Western Latin, Apostles', Athanasian) but only one recension is wired up at v0.
- This is a tool, not a teacher. Even at v1 with theologian-authored data, the validator is a content-moderation aid for a human reviewer, not a substitute for theological judgment by competent human authorities. The system flags candidates worth a closer look; a person makes the call.
From v0 prototype to v1 publishable system
Next milestones
- Theologian-authored corpus (Q3 2026). Commission ~300 dev cases plus a held-out audit set from ecumenically-distributed theologically literate annotators. Existing seed set retired to validation-only.
- Personhood / Trinity axiom cluster (v1). Implement ADR 0003 to handle modalism and the economic-trinitarian drift cases v0 currently misses. Expected lift on the CONTRADICTS row.
- Held-out evaluation under reviewer audit. First held-out run is a single-author benchmark; the second pulls a wild-type subset from real sermons and theology blogs to test out-of-distribution behavior.
- Multi-recension config. Apostles' Creed, Athanasian, and the Western Latin Filioque recension as alternative ontology instantiations — same code, different YAML. Selectable per platform partner.
- Audio-modal extension (v2). Apply the validator's logical-form parser to lyric transcripts and sermon transcripts already in the Rejoice catalog — first as an internal trust signal, then as a consumer-facing "creedal alignment" badge for opt-in platforms.
- Baselines and ablations for publication. Compare against zero-shot LLMs (with and without chain-of-thought, with and without the Creed text in-context), against a fine-tuned NLI baseline (DeBERTa-v3-large-MNLI), and against a deliberate rule-piling control to operationalize the central architectural argument.
Built within the Pulpit to Pages research program on theological AI evaluation. Methodology draws on prior work in adversarial NLI (LogicNLI, FOLIO), calibrated selective prediction (Kamath, Jia & Liang 2020), and neuro-symbolic reasoning (NeuralLog, ProofWriter). The rule cascade is documented in docs/parser_design.md; calibration in reports/calibration_v0/summary.md.